Not digital recognition. Human recognition.
The tiny moment before a greeting where your brain races to answer impossible questions: Who is this? Have we met before? Why do they know my name? For most people, that moment passes instantly. For others, it becomes a daily source of anxiety.
That’s what led me to build Memory Mirror.
It started after reading about prosopagnosia, or face blindness, a condition that affects nearly 1 in 50 people. But the more I researched, the more I realized the problem stretches far beyond that label. People dealing with age-related memory decline, early dementia, cognitive fatigue, or even chronic stress often experience the same quiet friction. Faces lose context. Conversations begin with uncertainty instead of comfort.
And socially, the consequences compound slowly.
Missed greetings. Awkward pauses. Pretending to remember. Avoiding interaction altogether because recognition feels unreliable.
I didn’t want to build another intrusive AI assistant hovering over people’s lives like a fluorescent intern. I wanted something calmer. Something ambient.
So Memory Mirror became an experiment in using on-device computer vision as a kind of cognitive prosthetic for recognition.
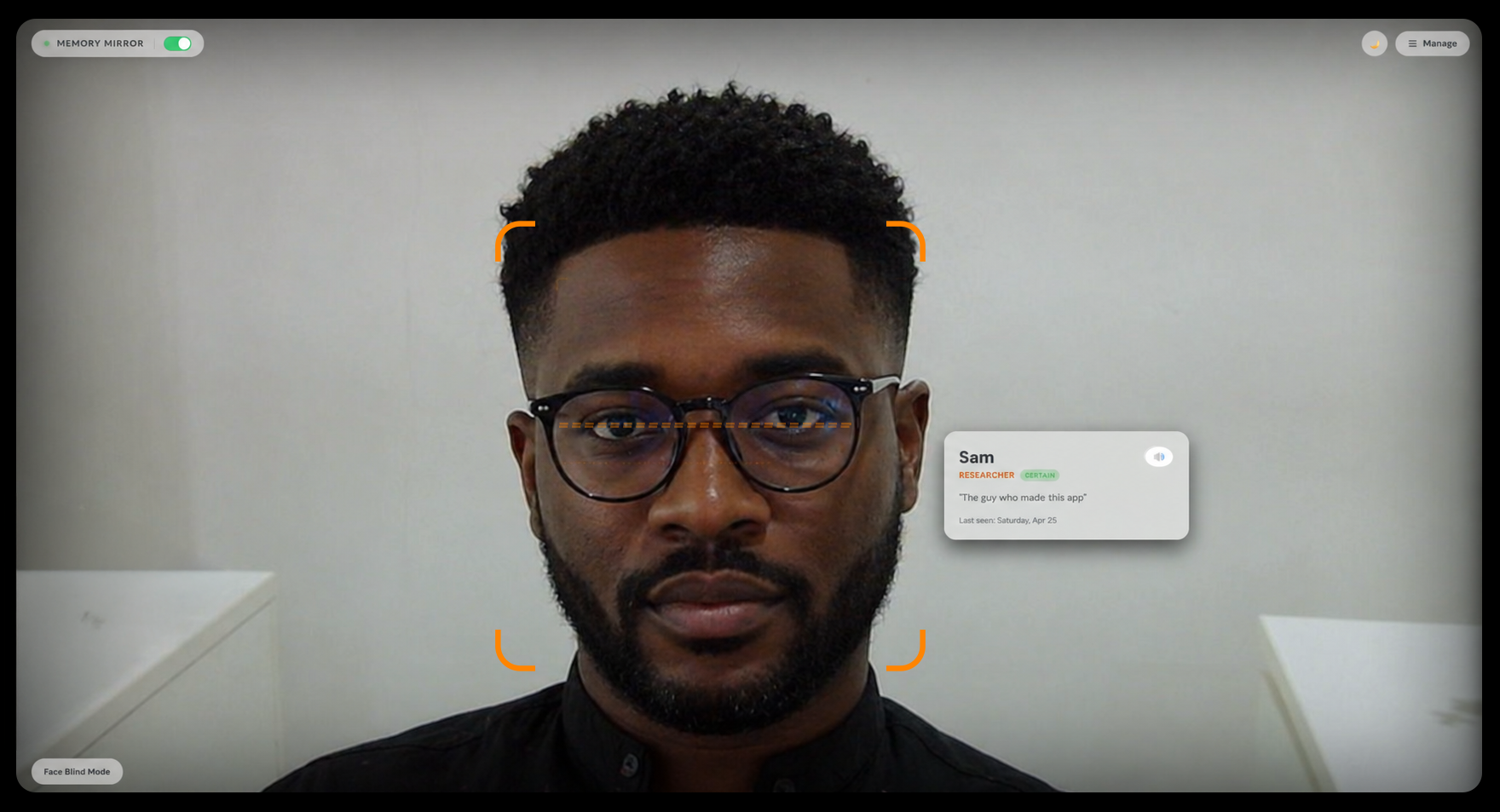
The experience is intentionally simple. A laptop or tablet sits nearby with the webcam pointed toward the room. When a familiar face appears, a soft memory card fades in beside them showing their name, relationship, personal notes, and when they were last seen. The user glances at the screen, regains context, and returns to the conversation naturally.
No searching. No commands. No friction.
Almost like a second memory quietly sitting beside you.
What fascinated me most while building it was how invisible the technology needed to become. The goal was never to impress people with AI. The goal was to reduce social fear so effectively that the interface itself disappeared into the background.
In a strange way, Memory Mirror is less about facial recognition and more about preserving confidence. Helping someone stay present in a room instead of retreating from it.
You can explore the project here:
Memory Mirror