It’s been a while since I built this LoRA evaluation project, but I still find myself thinking about one strange observation from it.
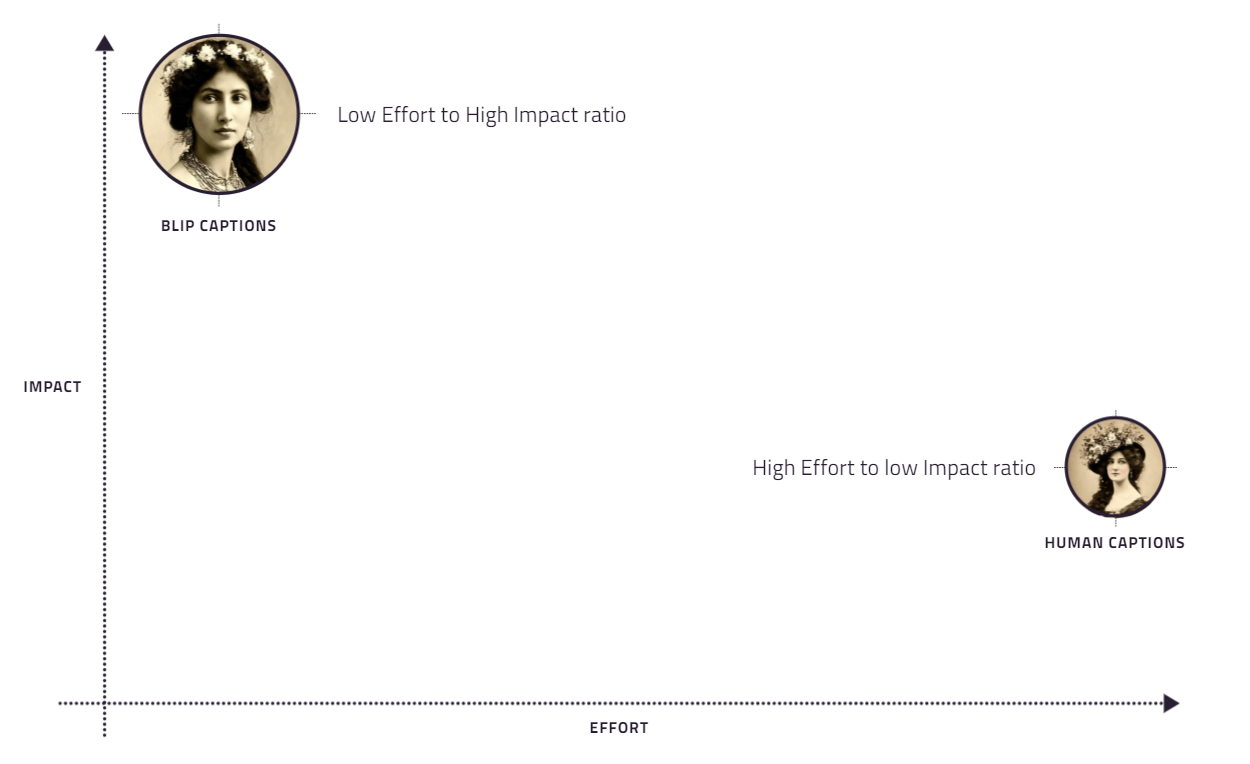
The automated captions generated through BLIP consistently outperformed the prompts written manually by humans, including mine. At first, it felt purely technical. Better tagging. Better consistency. Better semantic coverage. The usual machine learning explanation buffet.
But the longer I sat with it, the less satisfied I became with that answer.
Because humans don’t describe images objectively.
We describe them through memory, exposure, emotion, culture, vocabulary, insecurity, obsession, and omission.
Two people can look at the same image and produce entirely different prompts because they are not just seeing the image. They are seeing themselves reflected inside it.
One person notices fashion details because they grew up around textiles. Another notices lighting because cinema shaped how they observe the world. Someone else completely ignores the background because their brain attaches emotionally to faces first. Even silence becomes part of prompting. Sometimes we know exactly what something looks like but don’t possess the vocabulary to name it.
That gap fascinates me.
A machine like BLIP doesn’t carry heartbreak, nostalgia, prejudice, aspiration, shame, taste, or aesthetic insecurity into the captioning process. Humans do. Constantly.
And then there’s another layer: emotion itself. Happiness sharpens attention differently than grief does. Trauma changes salience. Bias changes what feels “important” enough to mention. Prompting is not just a technical act. It’s cognitive archaeology.
Looking back, this project stopped being an evaluation of LoRA datasets and quietly became an evaluation of perception itself.
Not “humans write bad prompts, machines write good prompts.”
But rather:
Humans write prompts through the unstable lens of being human.
And honestly, that complexity makes the whole thing far more beautiful to think about.
You can explore the project here:
AI LoRA Evaluation